 |
||||
  |
    |
|||
|
||||
|
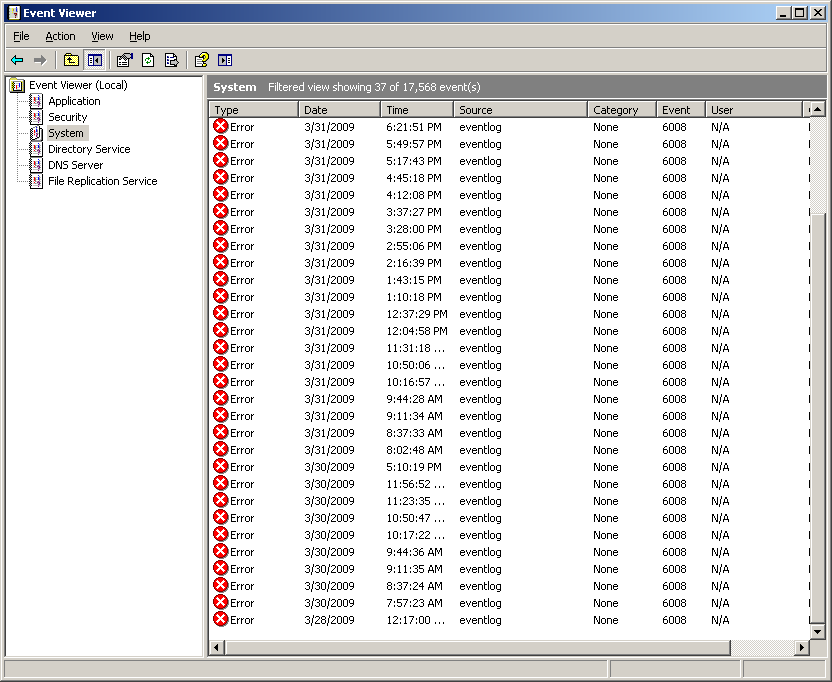
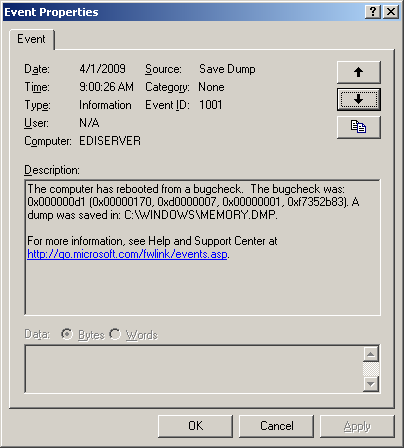
Your system has a bad drive and Dell / Adaptec's defective driver is crashing rather than being "Fault Tolerant" the way a real RAID system would be. Replace the drive(s) and move on to more important things as the storage cost is cheap compared to how many hours you can blow on this. Read on for more technical meat than most probably want to read. Background and symptoms I got the call one morning -- their server seemed to work for awhile, then not work, then work again. It was rebooting on its own. I arrived on-site and immediately went to the event viewer and found a series of reboot events -- one on 3/28, then a bunch on 3/30 -- each 35-45 minutes apart, then took a break from rebooting till 5:10 PM, then resumed its rebooting every 30 or so minutes the entire next day. You can see the event log's screen filtered for these events here I found the blue screen event as well, and that screen is here The save dump log reads as follows: The Event ID: 1001 Source: Save Dump The computer has rebooted from a bugcheck. The bugcheck was: 0x000000d1 (0x00000170, 0x00000001, 0xf7352b83). A dump was saved in C:\WINDOWS\MEMORY.DMP |
||||
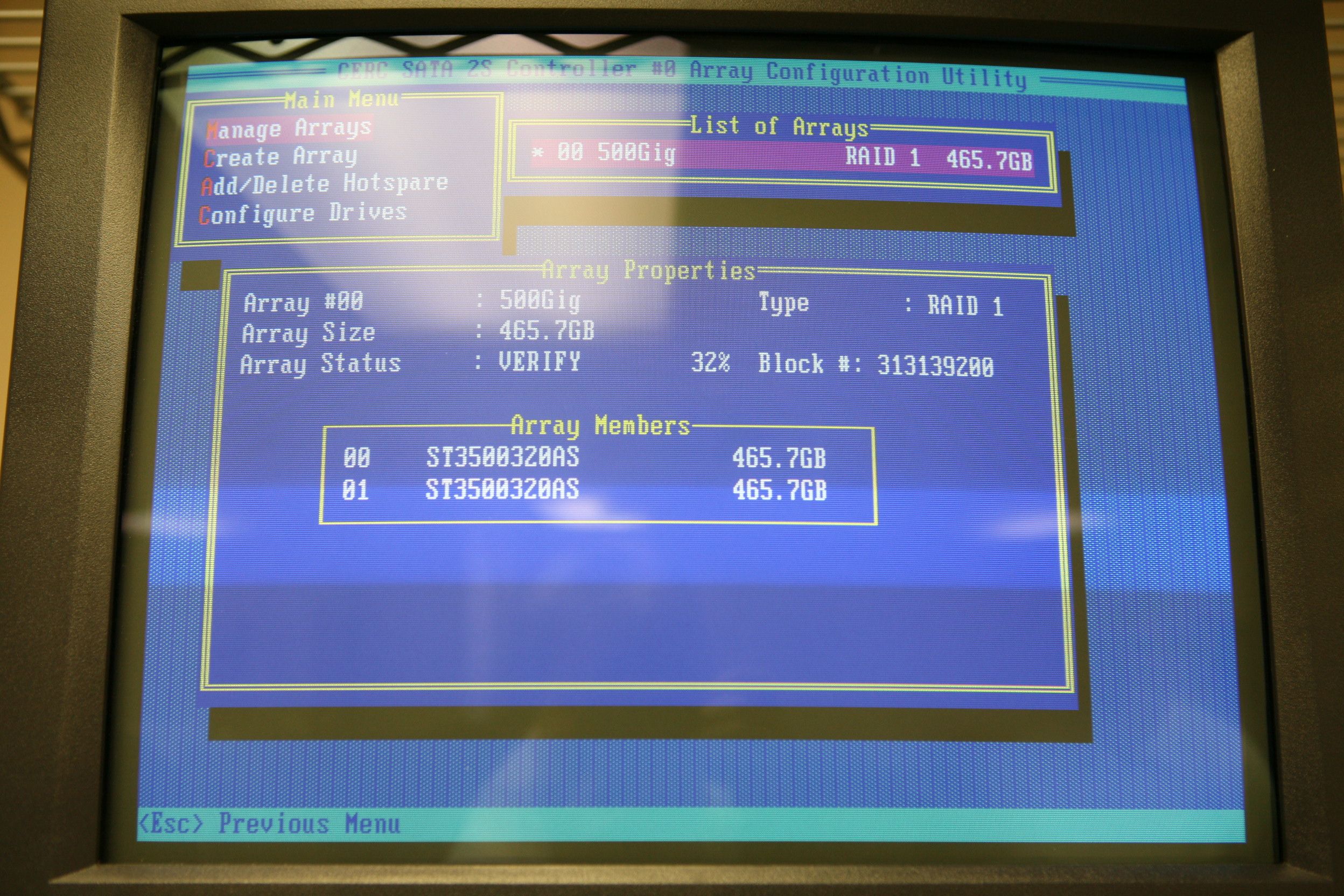
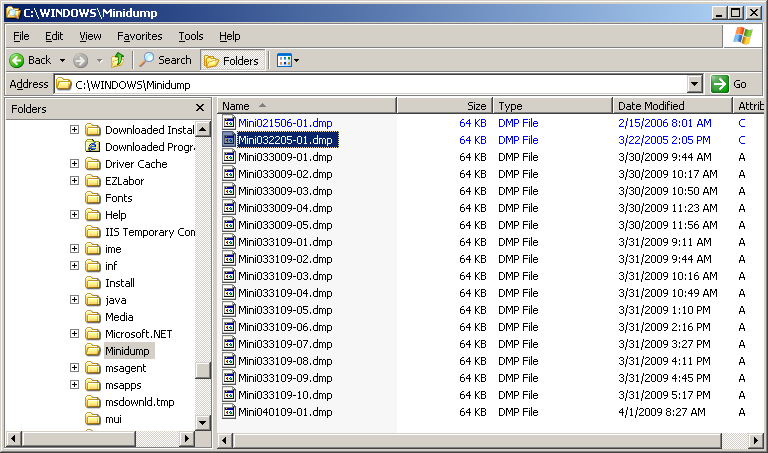
| The mini dump directory had quite a lot of dumps from the bugcheck events. Not quite one for each, but enough. The bugcheck directory can be seen here I did the requisite searching on google and yahoo for the address of the address of the failure, 0xf7352b83, and found nothing. Other checks found problems that were the same kind of bug check, but nothing was similar enough to warrant further investigation. So it was onto actually loading up the minidumps into the Microsoft Debugging Tools (windbg.exe) and see what it had to say. The output of the crash dump can be read here. The important parts from the crash dump were: Probably caused by : aarich.sys ( aarich+9b83 ) And the fact they were all the same error. Lots of companies like to blame the BSOD on flakey memory, an overheating processor, or stray alpha particles causing bits to flip in memory. When you have the same error happening over and over again, chances are the software is doing exactly what it was told to do, which isn't often exactly what the engineers thought they told it to do. For the purist debuggers out there, I did make a leap. Trust me on this one. In fact, there is a saying I heard in my youth. "If builders built buildings the way programmers wrote programs, the first woodpecker that came along would destroy civilization as we know it." As someone who has written tons of code in many different languages, I can tell you that often times shortcuts need to be taken. It is a balance between getting it perfect, getting it good enough, getting to market first, getting it done as quickly as possible, getting it done as cheaply as possible, getting it done with as few people as possible, ... It is a balancing act tough to understand if you haven't lived it. Sorry - I digressed. Back to the problem and analysis. Searching for the aarich.sys driver and its function in life, it turns out this is the RAID driver for the on-board CERC SATA 2S controller, a software based in firmware RAID that abstracts your two drives into either a single stripe or mirror drive. This system had two Seagate ST35003200AS 500GB SATA drives setup as a mirror to protect from drive failures. Soooo, lets think about this for a second ... a driver that controls the array has a catastrophic failure at reasonably regular time intervals. What could it possibly be doing? For the search engines: aarich.sys came up as version 6.0.50.5, dated 2/17/06 11:03 AM, and identified itself with the string "Adaptec Host Raid" A quick trip into the array manager and the array was being verified, and waiting till the clock struck 45 minutes the verify was around 33% and the system blue screened, right on schedule. When it returned, the verify started up again -- from the beginning. Checking versions, the drivers were already the latest from Dell, but I reinstalled them anyway, as well as checking other drivers, BIOS version, etc. The system was 100% up to date. So, I was about to initiate a call to Dell technical support when I thought of something. The repeating BSOD time interval evidence seemed to indicate it would blue screen every time it got near or on the same point in the array verification process. So my theory was this was a bug in the verify that the driver did under Windows. Perhaps the bug was only there and the BIOS array verification, if allowed to complete and could fix the error, it would mark the array as clean and thus next windows boot there would be no verify necessary. Something was triggering the BSOD, and during an array verify the two identical sectors of the array are read and possibly re-synchronized if they were found not equal. So my theory was that the same numbered block on both drives was giving read or write errors, and that was running a seldom-if-ever corner case in the RAID driver code which had never been tested and was now causing the BSOD. With the verify running, I called Dell. They went through everything I'd already done -- checking versions, checking BIOS, looking into their knowledge base, etc. Dell has a tool that is >really< nice, something I'd never seen before and have to mention. It is called DSET. This tool runs on your system and gathers up tons of information on the hardware, software, drivers, errors in event logs, ... and packages them all up into a zip file which when unzipped (password is 'dell' all lower case) so you can ship them to Dell for analysis. Or, if you are a consultant (hint hint) -- have your client run it on his dell and send it to you!
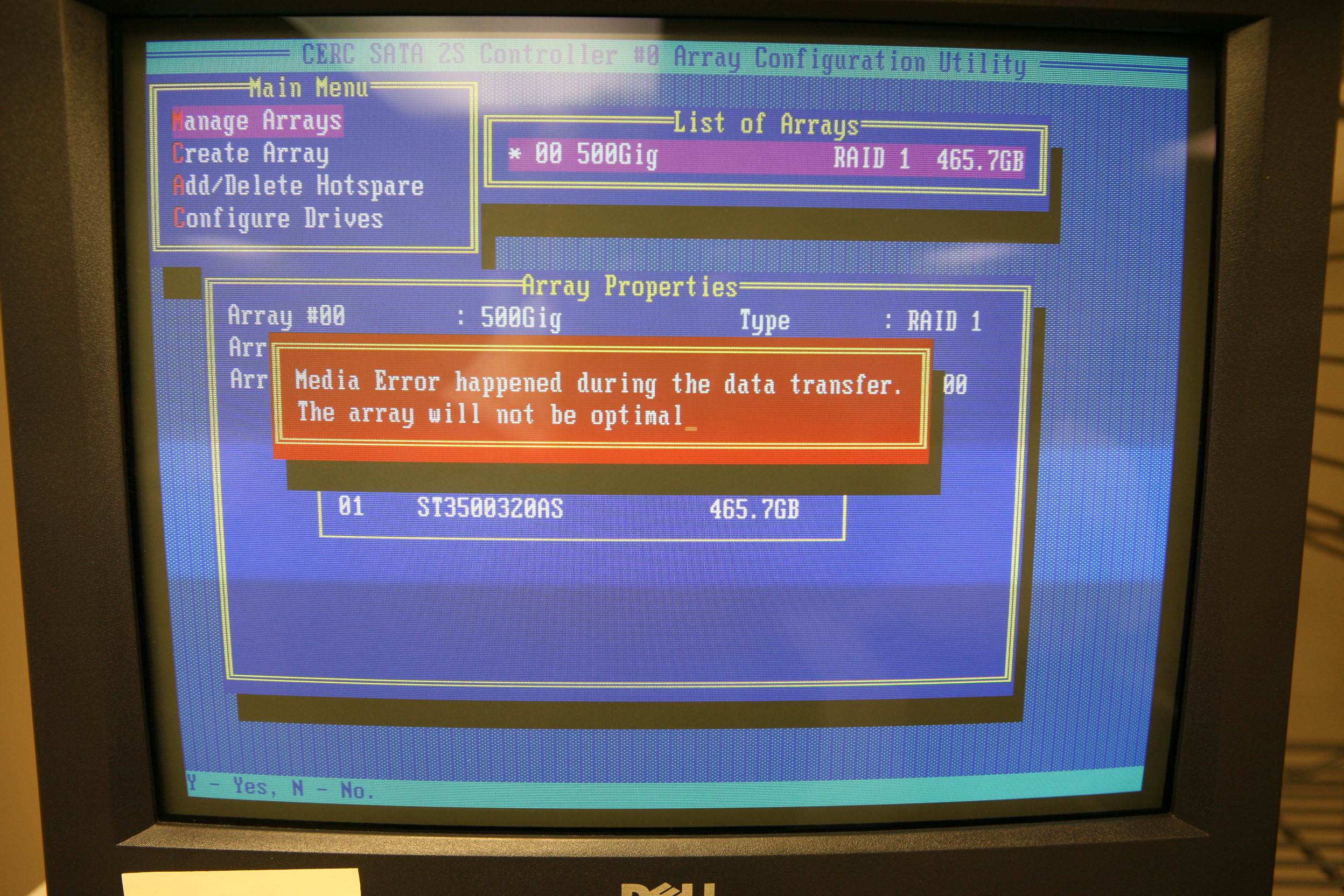
Here is the DSET link They had a couple of other cases that were similar and were getting a team together to look into the problem. They sent me an updated scsiport.sys, which their install utility said I didn't need as it was already installed. The 2 hours Dell support phone call yielded nothing, and when I hung up I started the system back on the BIOS disk verify path, calculating out it would finish in ~4 hours. I briefed the client on the status, said I'd clock out and work on some other things I had to do for another project while the verify happened, see if the BIOS level verify will fix the error, mark the array clean, and while the root of the problem would remain hopefully the system would be stable enough for a day or two. If it isn't, I'd stop into the last standing computer store here in southeast Michigan (Micro Center) and pick up a couple of drives to migrate the system onto. I recommended he let me do that over the weekend -- if I did it while sitting on-site, the bill would be incredibly large as it takes hours to copy and hours to build arrays on drives that size, and these were things I could start overnight or during the day and occasionally check VS. having to stay at their place of business while watching the paint dry. It is never cost effective to pay someone to watch the paint dry! The array verify stopped right around that 33% mark with the following screen, which demonstrates complete stupidity on the part of the software engineers that wrote this code. There's that woodpecker knocking down the house again. Look at the screen and try to decide if you should hit Y or N to continue rebuilding the array:
The code is clearly telling us that an error occurred and that it can't do something -- but is it asking us "Do you want to continue with the verify?" in which case I needed to hit Y, or is it asking "Do you want to abort the verify?" in which case I'd want to hit N. As a fellow software engineer for the last 30 some-odd years, there are many times I'm embarrassed and ashamed of my craft, and this was one of them. Please, if you write code, don't ever write crap like this. We are long past the days of needing to save very byte in memory we can. I flipped a coin and hit Y. My coin was correct, as the verify continued:
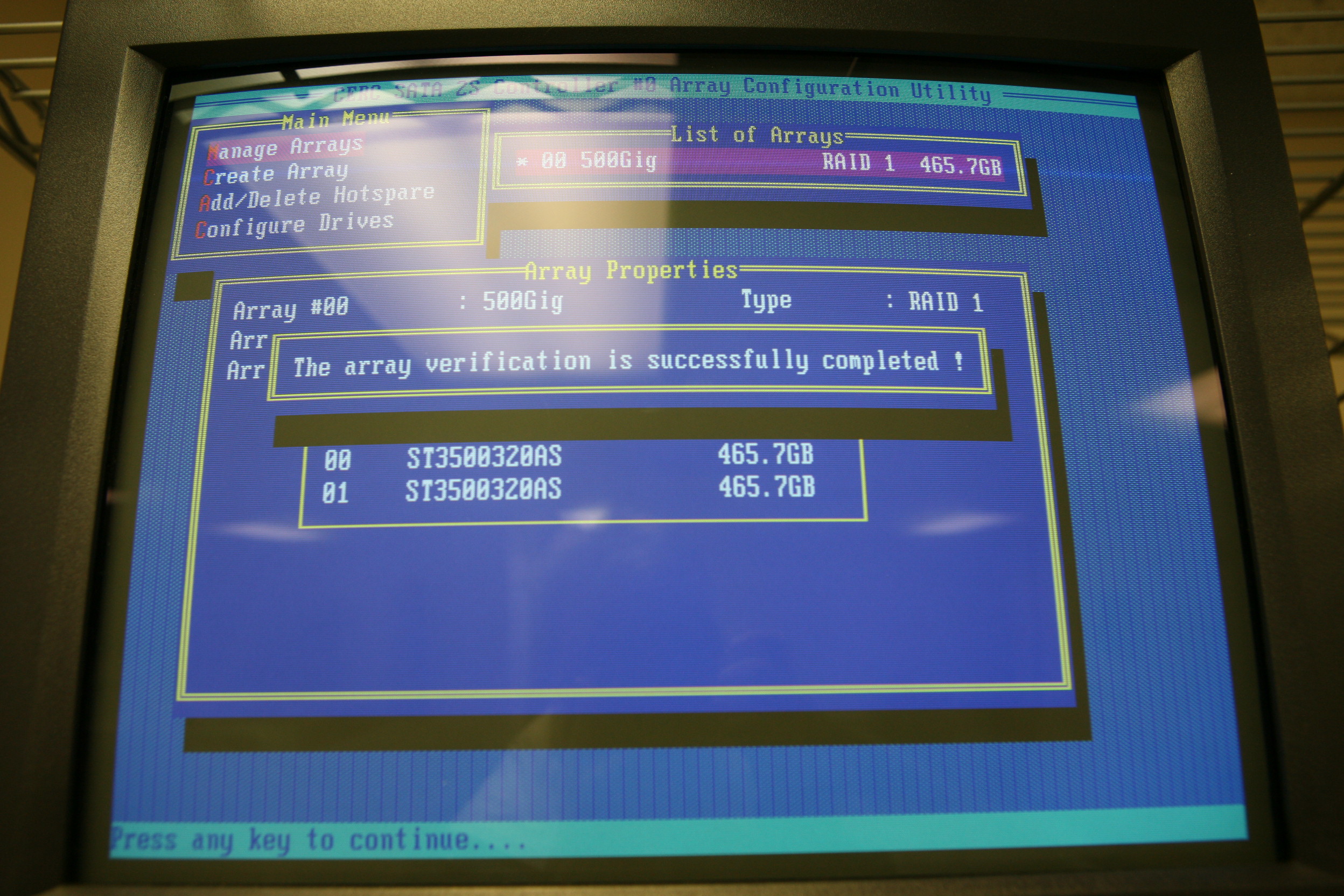
The same prompt came back about 5 or 6 times, all right around that 32% mark. Curiously, when it was all done building the array it said 0 errors found and 0 errors fixed.
The array finished building right around 4:30 PM, the system rebooted, and the array manger said the array was healthy and thus not rebuilding! So now it was a waiting game -- perhaps it was stable for now, perhaps not. I'd planned to wait a bit and see if it rebooted, but with it not verifying there was a chance it was reasonably stable. So I left and stopped in to pick up a couple of drives on the way home. I left a message in notepad on the screen: "If you can see this message, the server didn't reboot overnight! (YAY!!)" The next morning, the client said that the message was gone, the server was at the login prompt, and thus the server had rebooted overnight, so arrangements were made to have the system dropped off on Friday. During the day on Friday, I called Dell back to see if they were doing anything with the driver, and the word came back that if anything was going to be done it wouldn't be for at least a month, maybe more. Which made me very glad I was already on-track to fix this for the client in another way rather than expect / hope / wish Dell would fix the problem in their driver. Independently, I did some research on the Seagate Barracuda 7200.11 part number 9BX154-303 running firmware DS15 and a date code of 09127 site code KRATSG, product of Thailand -- apparently there was a problem with a bunch of these drives turning into bricks which Seagate identified and they claim fixed via a firmware update you can find here. There are other people complaining of other kinds of issues with these drives, so many that the forum moderator closed a bunch of them and pointed everyone at a new thread to collect these issues in one place. That thread, started on 2/3/2009, is now (4/3/2009) 68 pages long and has 10 messages on each page. The thread detailing lots of people with 7200.11 drives with issues can be found here. Now, this doesn't mean these drives suffer from any particular problem, but given the apparent surface errors and issues this Seagate drive model could also be another case of the "IBM Deathstar" drives. In all fairness, I had at least 4 of the Deskstar drives running 24/7/365 for at least 5 years without any issues, both 40 GB and 60 GB models. I also had a lot of clients with them that also never had an issue. When you make millions of hard drives a year, you are going to have drive failures and those people with failures that are vocal can now find each other due to the Internet. Is that what is happening here? Tough to say for sure. But it didn't give me a warm fuzzy either. Friday afternoon when the system arrived, I pulled one of the drives, connected it to another chassis, and made an image copy from the 500 GB Seagate drive onto the new 500 GB Western Digital drive. Installed in the system with another WD drive, then told the RAID BIOS to mirror the two from the just copied drive, and let it cook over night. Saturday morning, checked everything out and things looked really good. All the files were there, opened up a few of them, data looked good inside, the SQL database was starting up just fine for their ADP Payroll that was going to run on Tuesday. Later that afternoon, I decided to run a full backup and found the Volume Shadow Copy Service (VSS) was crashing miserably. But that is a different article, which I'll link here once it is written. With VSS fixed, did a bit more to get general health on Sunday, delivered the system Monday, and I've got one happy client about to run their company's payroll. So, the end result? If you've got these BSOD problems with this controller card, you've probably got a pair of drives that are throwing errors. Replace them both ASAP and your BSOD problem will go away. This is working around a driver problem that never should have happened. Which is (sadly) something we have to do way too often. The pair of 7200.11 drives got a full workout with Seagate's Disc Wizard tool, doing the long test a couple of times on Sunday. I even put the two drives directly on top of each other so they'd cook and were too hot to touch, and both passed the Seagate tests. In other words, I think I'd have a hard time getting them RMAed by Seagate. It is entirely possible the drives eventually did detect their bad sectors and relocate them, but tough to say for sure without historical data from the S.M.A.R.T. subsystem. Do I trust these drives? No. Not when for $77/each I got a pair of Western Digital Caviar Blue drives that have half the cache but hopefully will store and recall all their data. ------ Update, 4/12/2009: Offline, on a different system than the original Dell, I beat the heck out of both drives. Drive #0, copying many very large files to it over and over again. It never blinked. I then tried to beat the heck out of drive #1. It ran for awhile, then did a long pause. While pausing, you could feel the head skipping about in a repeating pattern. Then the drive would completely disappear from Device Manager, as if I had unplugged the SATA disk. A few minutes later, giving a refresh command to Device Manager would make the drive re-appear, and I could repeat the failure over and over again. Mind you, while the disk was working I could run Seagate's Sea Tools and test the disk and it says "All good here!" So there you have it -- drives are on their way back to the client, who will probably destroy them. They've decided it isn't worth the risk of their company employee's personally identifiable information leaking out -- remember, this was their payroll server. ----- If you found this helpful or not, please send me a brief email -- one
line will more than do. If I see people need, want, and / or use this
kind
of information that will encourage me to keep creating this kind of
content. Whereas if I never hear from anyone, then why bother? |
||||

{kind=link}
{kind=link}
{kind=link}