|
||||
  |
    |
|||
|
||||
|
|
||||
|
I see dead
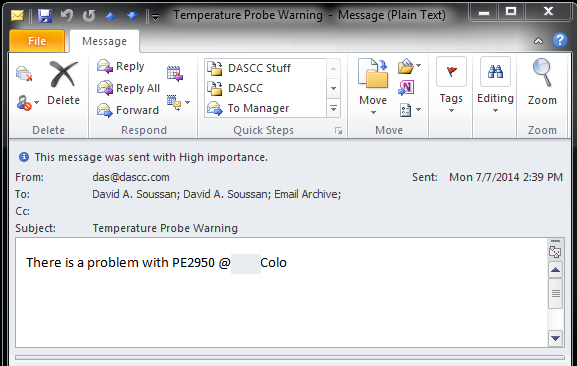
systems What prompted this article was a recent trip to a data center. I have client's equipment installed there and discussed an incident that happened back in the summer with people who work there. Last July, I received an alert warning. I got one in my main email box (pictures are thumbnails, click on them to see the full size screen snip):
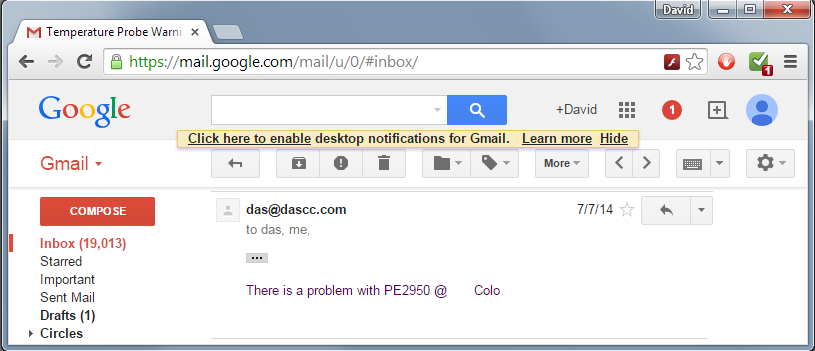
I got one in my backup email box on gmail:
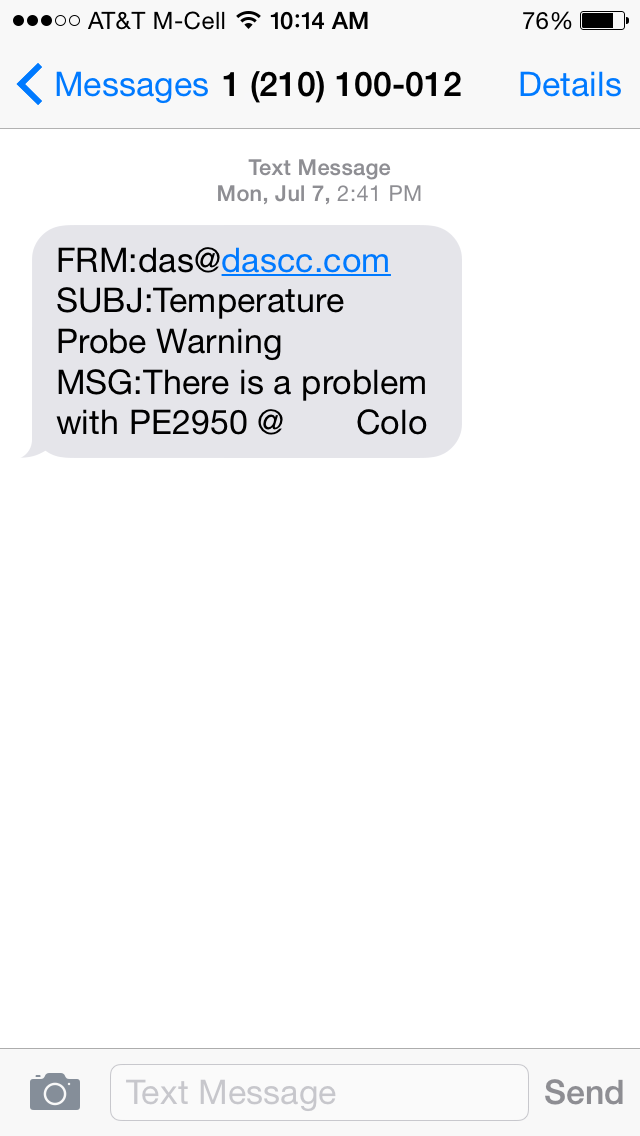
I got a text message on my phone:
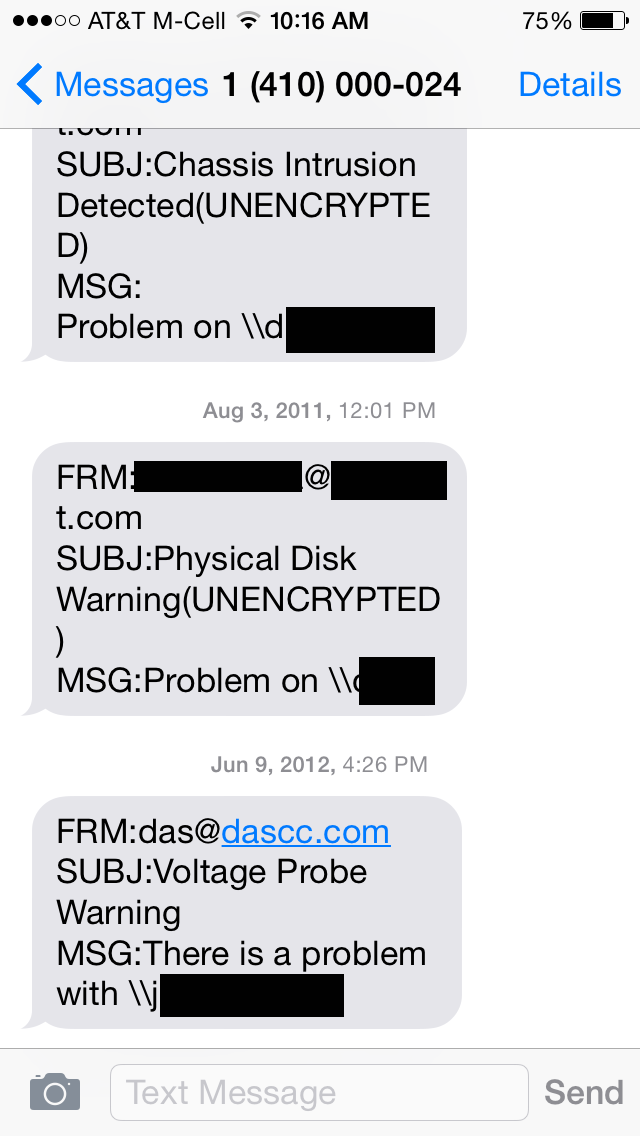
Now this server didn't crash. This server wasn't in any way shape or form impacted by these alerts.... YET... This was like your kid coming into the room in the middle of the night, poking you in the stomach, and saying "Daddy, my tummy hurts." Maybe it is nothing. Maybe he ate too much ice cream at the birthday party he attended earlier. Maybe it is significant. Maybe it is appendicitis. But if your door is locked and he never comes in and never tells you ... think of the potential consequences. Things could turn very bad very quickly, even passing the point of no return. 100% easily preventable. I'll circle back to the alert above at the end of this article and why this was so critical. Here are a few more alerts I've received throughout the years from various clients or my own systems. I'll just show you the text message versions instead of every flavor, but I have these set to alert me in 3 different ways along with the owner and / or technical contact at their company.
Up top, someone opening up the case. This happened at my direction, so no problem there. Next a disk failure. Every hard drive will fail at some point in its life, taking all the data with it. RAID protects you from a hard drive failure ONLY IF you replace the failed drive and let the redundancy rebuild. 2nd hard drive fails, now you've got data loss. Yes, there are ways of mitigating against N hard drive failures, but at some point if you aren't watching and fixing things the N+1 hard drive will also fail and you'll be in the same data / system loss situation. Drive replaced, system kept going without even needing a reboot! The bottom was a power supply looking over the edge of a cliff, ready to jump off. Power supply replaced, system kept going without even a reboot. This next one is a great story, with a timeline:
Sunday, 11/6/2011: 3:56 PM - power supply throws an error, I received various messages, remotely check in and confirm the failure:
I called the client's cell, he was on the road somewhere in Michigan driving back to their home office in Wisconsin. It is an older server, no spare parts, no service contract. Knowing his location, I know there are a few ways he can travel back to Wisconsin that aren't that much different in distance from each other. 4:09 PM - I've located a used server for sale on eBay that is along one of his paths home. Sent the seller a message asking if it could be picked up in the next few hours. He calls me, I explain the situation, get detailed directions, and have everything arranged. 4:31 PM - Purchase confirmation from Paypal. 4:42 PM - I've finished writing up all the details to email the client so they have all the pertinent details at hand. 4:43 PM - On the phone with the client, verbal instructions for what is already in the email... since you shouldn't be checking email while you are driving! Instead of going home via I94, instead they'll take 294, exit, couple of turns, make a phone call, and the server will be brought to the back of his truck. Then on with his journey home. 7:30 PM - Server is brought to his truck, he continues with his journey. Monday, 9:00 AM: I talk a non-technical office staff member through swapping the power supply. Takes 5 minutes tops. Server doesn't even need to be rebooted. No lapse in service. That spare server serves as an organ donor for a few more parts until the server is eventually retired and replaced. That spare parts organ donating server cost only $200! That is the kind of service everyone should get! How do I get that failure monitoring for my systems?Great question! If I've installed your server, you probably already have it. If someone else installed it, who knows? Next time you are at your data center or walk into your computer room, find one of the servers that has dual power supplies and unplug one of them. Go ahead! Now wait. See how long it takes for someone to show up and check if there is a real problem or if it is a false alarm. If nobody ever shows up, nobody calls, nobody cares, then you've got a problem waiting to bite your sensitive parts. Geeky stuff alert - skip if you aren't technical:This isn't a full walk through, more a 50,000 foot high view into "How you get this easy and free" On a Dell Poweredge, you must install and configure Dell's OPENMANAGE™ Server Administrator as shown here on one of my servers:
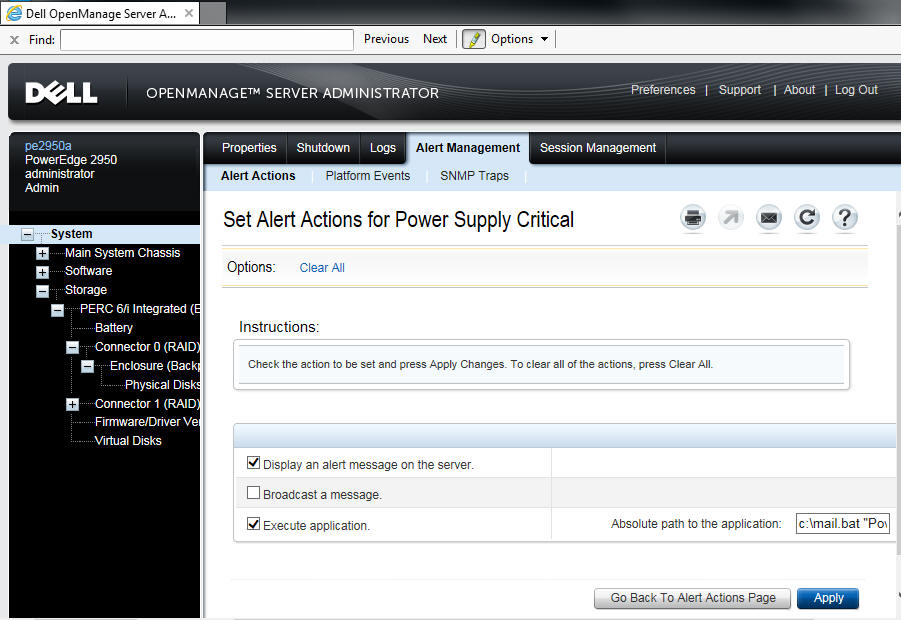
Configure all the alerts to run an application, then write a batch file to email you and anyone else in the event of an emergency. Here I've done it for the "Power Supply Critical" event:
I use BLAT.EXE to email me and my client at various addresses using the text message gateway to also send the alert to my phone via a text message. HP has a similar program, HP Systems Insight Manager with pages and pages of various alert possibilities, here is a snip from one of the last pages:
So CONFIGURE THOSE ALERTS! The data (and job) you save may be your own! It is 10:00 PM. Do you know that YOUR servers are healthy?I know mine are! I know any I've installed for my clients are! What brought this on - I was at the data center and could hear a server beeping every couple of seconds. As loud as it is there, I could still hear the beeping. From the frequency and cadence of the beeping, I can tell it is a Dell server with a drive failure. Somewhere somebody is going to have a very bad day if they don't fix it soon. The server wants to be heard! It wants to be well! It is crying ... and nobody was listening. I informed the management staff, they contacted the client, and when I went back two weeks later the server wasn't beeping anymore. The alert I opened the article with - the temperature probe alert - turned out to be a problem with a cooling unit at the data center. They were already on it, had setup a temporary backup cooler until the main unit could be replaced on Monday. I asked "How many other people called asking if there is there a problem at the data center or do I have a server that is overheating and I need to investigate?" Of all the clients, only one other called. This tells me lots of servers out there are not configured to call out for help when they have problems. Why??? I can't think of one good reason this wasn't done. If this configuration takes someone more than an hour, they should not be setting up servers. If you would like the same features on your systems, I would love to help out. Full contact infomration is at the Contact Us link on the top left of
this page, and I can be reached at: David Soussan (C) 2015 DAS Computer Consultants, LTD. All Rights Reserved.
|
||||