|
||||
  |
    |
|||
|
||||
|
Here is the TL;DR version - DON'T BE CHEAP - INSTALL THE WRITE CACHE AND BATTERY! You can stop reading now. Background scenario I have a client with a bunch of systems at a local data center. When I received this 600 pound pile of equipment, I allocated each system to various tasks based on what was inside each server - dual CPUs, dual power supplies, and lots of memory? You are a server hosting multiple virtual machines. What was left was a single CPU machine with lots of open drive slots, a single power supply, little bit of RAM, no cache battery ... pretty stripped down machine. He became a backup data repository after getting an infusion of hard drives. |
||||
|
Once everything was racked and running, I setup the backup system and monitor it regularly to be certain things are backing up. I've also written about backups and how important they are so I won't get on that soapbox now. News: More servers will be here soon! That was a message I received recently - there are two more servers that will arrive in the next couple of months and they will be housed in the same rack. I took a look at the backups and how long everything was taking to see if there was bandwidth in the current setup or will I have to setup something different to receive the backups for the new servers. Here are a few samples and a bigger graph.
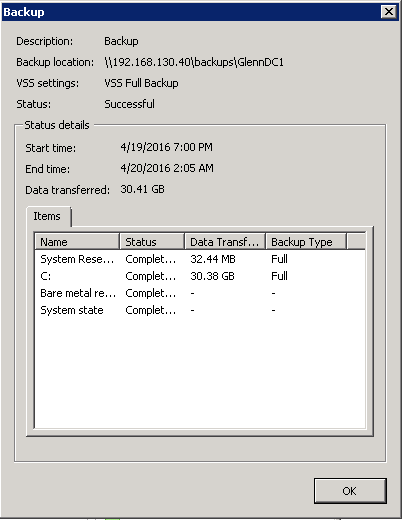
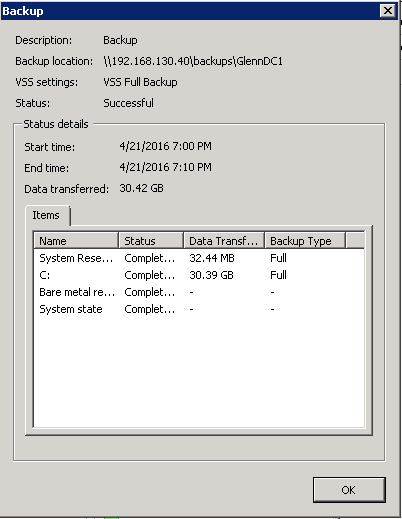
This is one server - his size is 30 GB, the backup starts at 7 PM and ends at 2:05 AM the next morning. Total duration is 7 hours. A second server is shown here:
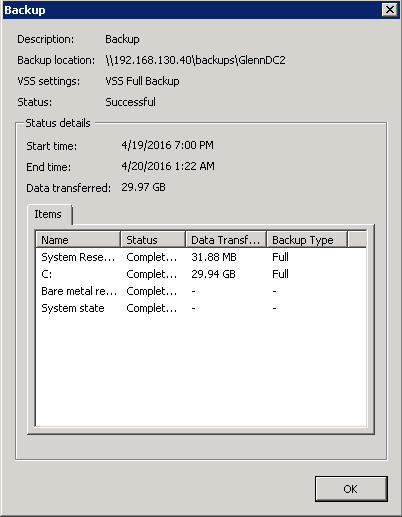
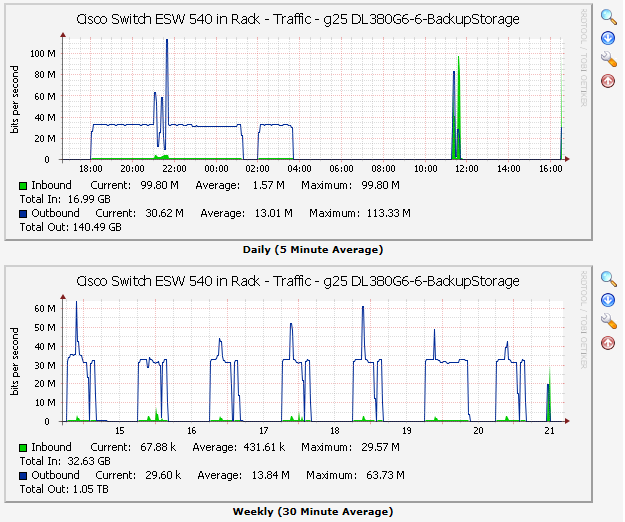
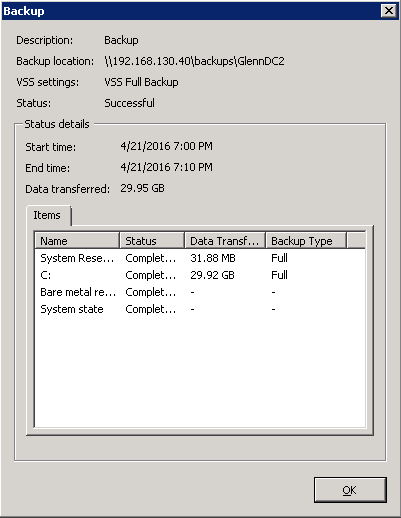
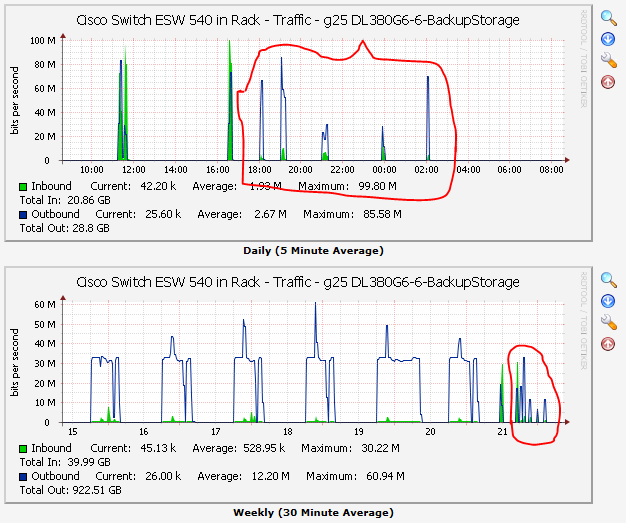
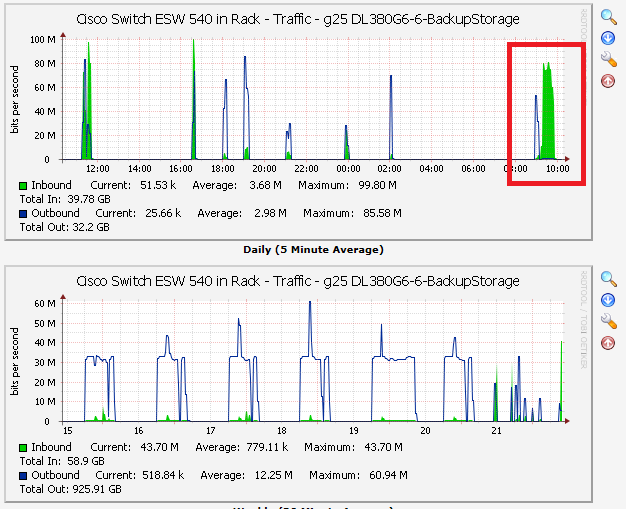
This system also started backing up at 7:00 PM and finished at 1:22 AM the next morning, so 6 hours and 22 minutes. Seemed a little slow, but was good enough for the job at hand so I didn't spend any time or money optimizing it. I graph the traffic at all ports of the switch, here is what the whole backup window looks like for all systems - 1 day on top, 1 week on the bottom:
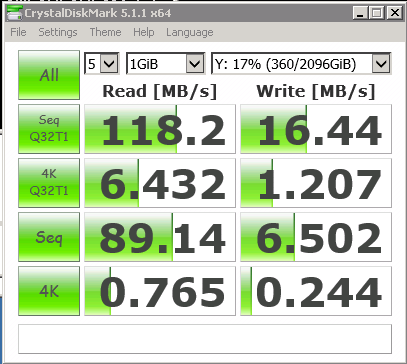
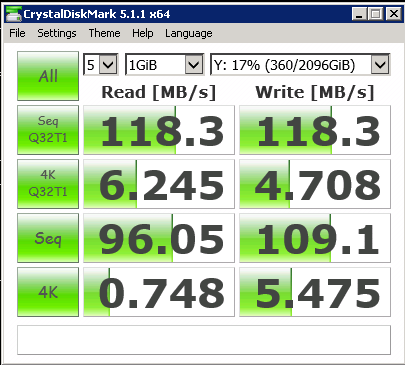
I really like these kinds of instant visual aids - with one look you have a really good idea if things are working normally or if something has turned brown. That little green and blue spike at 11:30 in the upper graph and just above 21 in the lower graph? That is me doing some benchmark tests. Benchmark testing! Before making a big change, it is usually a good idea to take some quantitative measurements to see if you are going to have an impact with a change you are about to make. So I did that-Crystal Disk Mark has been a decent disk benchmark tool for years and I ran it from one of the servers to the backup location. I also ran it to local storage, another location on the same server, a location on a different servers, etc. to get a feel for just what kind of impact the cache memory will have if I were to install it in the backup server. Here are two sets of numbers, the first without the write cache and the second with the write cache:
The "read speed" numbers are boring. The "write speed" numbers are astonishing. 118.3 / 16.4 = 7.2 times faster at sequential writing
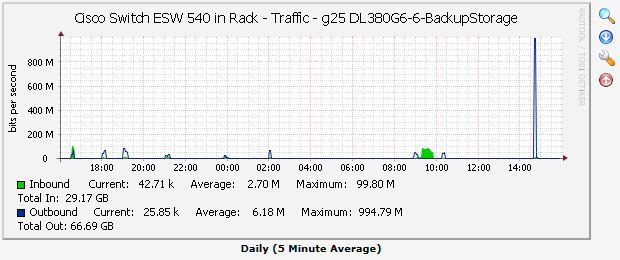
with a queue depth of 32! Benchmarks aside, how does this translate into real-world improvement? Remember those two backups? The ones that took about 6.5 and 7 hours respectively and started at the same time? Here they are again with the write cache forced on without the battery - which is not something I advocate for reasons I'll explain at the end:
Both finished in 10 minutes. In parallel. 7 hours is 420 minutes. 420 minutes / 10 minutes = 42 times faster... or more accurately both run in 1/42 the time as they do without the cache. And here is the network traffic graph:
... but something is very fishy about those graphs. The red circled traffic I expected to see a whole lot higher than they were. Feel free to click here to skip this next bit if don't care about the path I took questioning and debugging these results and just want the answer. Relying on your test equipment In the old days when you were in electrical engineering college one of the first times you got to touch real world EE test equipment they walked you through discovering measurement errors. You used a typical meter to read a very low resistance value and discovered there was resistance in the wires that lead to your device under test which threw your readings off. Or the meter itself had an internal resistance that impacted the circuit. I did some math on the 10 minutes of backup and how much data transferred. 10 minutes * 60 seconds/minute * 60 Mbits/second * 1 Gbit/1000 Mbit * 1 GByte/8 Gbits = 4.5 GigaBytes. If instead I pretend the scale is off and I'm really calculating bytes per second, the number came out to 36 GigaBytes. So is my scale on the graph off? I didn't think so - if it was, the other graphs would have been way off as well. So was the backup not actually happening but thinking it was happening? Was that much data transferring or was the backup program thinking it was transferring but throwing the bits into the bit bucket? A raw copy of about 36 GB of data took 5 minutes and looked like this:
In the red square the blue line is my file copy (36 GB in 5 minutes). I needed to verify, so I next did a binary file compare between the files I copied and the files at the destination system:
(picture is a thumbnail, click for a larger version) You can see the original copy, started at 9:00 AM, the time stamp when the files finished copying at 9:05, and then my binary compare of the first file - file compared exactly. So the copy was happening, but my graph must be wrong. The green blob is the network traffic from the file compare which took a whole lot longer probably because of the act of actually comparing the files VS. just moving the data. My theory was the graph wasn't accurate. Exporting the RRD and manually looking at the numbers, I concluded the number was wrapping around - fixed by moving the value collected to a 64 bit counter. My first 36GB file copy after making the change is shown on the traffic graph:
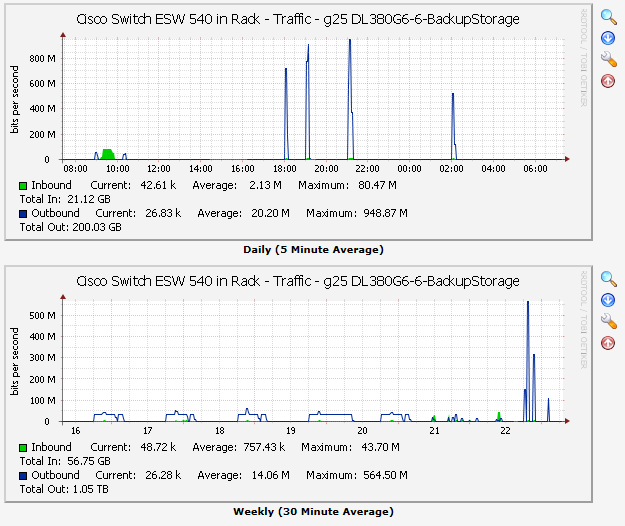
The big blue traffic spike on the right is huge, plus make note that all those other peaks were pushed waaaay down and the top of this graph is almost at 1 Gb/s! Now I'm feeling good about the traffic graph! If there was enough data in the 5 minute span, the counter would wrap and my traffic number was no longer accurate. I don't think it has been a problem up till now as the biggest data mover - the backup - was slow enough it kept the 5 minute traffic under the wrapping 32 bit counter threshold. Why aren't my traffic graphs passing a smell test? A lot of debugging later, it turns out I needed to use 64 bit counters for the port traffic as at gigabit speeds the traffic could wrap around the 32 bit value. The next morning with the correct 64 bit counter values for 5 minute traffic samples my backups looked like this:
You can see 4 backups traffic bursts, 6 PM, 7 PM, 9 PM, and 2 AM. You can also see the peak looks way more reasonable and due to the scaling pushed all the other graphs to be shorter. There is a big enough difference I might consider moving to a logrithmic scale instead of a linear scale, but that will be another day. Why are the backups 42x faster when the benchmark only showed 16x improvement? Great question! I'm going to bet it is because the two backups running at the same time were likely impacting each other as the target disks had to flip back and forth between writing for backup #1 and #2 constantly. In the geeky world, we call that 'disk thrashing' as the heads are spending so much time moving back and forth your abilty to write data is severely impacted by the speed of head seeks (very slow!) compared to writing sequential sectors. With the cache, some of backup #1 could be cached up and written all at once and the same with backup #2. With the heads moving around less both backups were able to complete at a reasonable speed. Conclusion If there is any doubt if you need cache memory when writing to hard drive arrays (or individual drives for that matter), this should make the answer clear - yes. Just buy it. And if your battery dies, you need to replace it. Your system will still run but the write performace will be severely impacted. A new battery for this HP server runs north of $140. I did a retro-fit for < $50 including labor:
But those details will have to wait for a future article! As for why you don't want to run a write cache without battery backup - write cache tells the system the data has been written to the hard drive right away even if the data is still sitting in the cache memory. If something were to happen to kill the system like a power loss or bus lock-up, the information the computer thought was on the drives isn't there. It could be a very critial to the system operation write like a major update to a directory sector. It could render the system non-bootable and require very intricate data repairs to bring back to life. With the memory backed up by a battery, this gives you time to fix whatever caused the crash and upon starting the drive controller will see the cache is dirty and empty it from all unwritten sectors of data, 'flushing' the cache contents back onto the disk. What I did was OK for a very short term item on something that wasn't critical for day to day operation. Or, to put it another way, "Kids, don't try this at home!" Final Words... If you found this helpful or not, please send me a brief email -- one line will more than do. Or more! I can be reached at: Copyright (C) 2016 DAS Computer Consultants, LTD. All rights reserved. |
||||